Objectively Evaluating Developers’ Cognitive Load
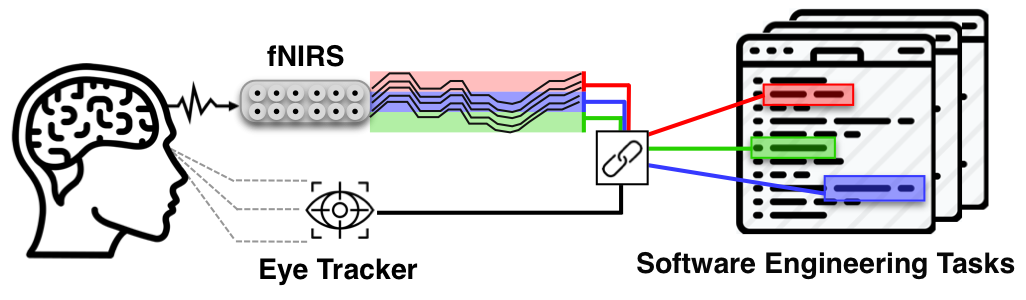
Recent research in empirical software engineering is applying techniques from neurocognitive science and breaking new grounds in the ways that researchers can model and analyze the cognitive processes of developers as they interact with software artifacts. For instance, researchers started using brain imaging techniques in particular functional near-infrared spectroscopy (fNIRS) and functional magnetic resonance imaging (fMRI) to understand what happens in developers’ brains. Applying such technologies in software engineering in general and in program comprehension, in particular, is crucial as they enable us to infer a causal relation between a studied phenomenon and a dependent variable and thus open up new possibilities for research. In a research lead by my Ph.D. student Sarah Fakhoury, we proposed a methodology and a framework to study developers’ cognitive load during software engineering tasks. In particular, we show how using eye tracking technology and an fNIRS device allows us to map and analyze cognitive load data at a very fine level of granularity, such as source code identifiers. Our methodology exploits the portability and the minimally restrictive nature of fNIRS and eye tracking devices to enable researchers to perform controlled experiments with developers in real working environments. Moreover, with the lead of my Ph.D. student Devjeet Roy, we propose VITALSE, a tool for visualizing combined multi-modal biometric data for software engineering tasks. VITALSE provides interactive and customizable temporal heatmaps created with synchronized eye tracking and biometric data. The tool supports analysis on multiple files, user defined annotations for points of interest over source code elements, and high level customizable metric summaries for the provided dataset. This work is supported by NSF (CCF-1755995 and CCF-1942228).
Additional information:
- EMSE’2020 Paper: Measuring the Impact of Lexical and Structural Inconsistencies on Developers’ Cognitive Load during Bug Localization; Replication package: here
- ICSE’2020—Tool Demo Track: Paper: VITALSE: Visualizing Eye Tracking and Biometric Data; The VITALSE tool: https://vitalse.app; Presentation: here
- ICPC’2018: Paper: The Effect of Poor Source Code Lexicon and Readability on Developers’ Cognitive Load; Replication package: here; Presentation: here
Improving the Readability of Automatically Generated Tests

Automated test case generation tools have been widely used to reduce the amount of resources used to write manual test cases. However, developers are still required to maintain these tests in response to the evolution of their source code. This maintenance effort is hindered by the poor readability of these tests due to their lack of documentation and unintelligible lexicon. In a work lead by two of my Ph.D. students Devjeet Roy and Ziyi Zhang, we propose DeepTC-Enhancer—the first approach to enhance both the documentation (by generating test case scenarios) and code (by renaming variables and test case names) aspects of automatically generated tests. An empirical evaluation with 36 external and internal developers shows that the transformation proposed by DeepTC-Enhancer results in a significant increase in readability of automatically generated test cases.
Additional information:
- ASE’2020: Paper: DeepTC-Enhancer: Improving the Readability of Automatically Generated Tests; Replication package: here; Presentation: here
Measuring the Improvement of Source Code Readability
Recent research suggests that more often than not, state-of-the-art code quality metrics do not successfully capture quality improvements in the source code as perceived by developers. In a research lead by my students Sarah Fakhoury and Devjeet Roy, we propose a model that is able to detect incremental readability improvements made by developers in practice with an average precision of 79.2% and an average recall of 67% on an unseen test set. Our model outperforms state-of-the-art readability models by at least 23% in terms of precision and 42% in terms of recall.
Additional information:
- ICPC’2020: Paper: A Model to Detect Readability Improvements in Incremental Changes; Replication package: here; Presentation: here
- ICPC’2019: Paper: Improving Source Code Readability: Theory and Practice; Replication package: here; Presentation: here
Linguistic Anti-patterns (LAs)

We define Linguistic Antipatterns (LAs) as recurring poor practices in the naming, documentation, and choice of identifiers in the implementation of program entities. We provide LAs detection algorithms in an offline tool, named LAPD (Linguistic Anti-Pattern Detector), for Java source code. In a research lead by my Ph.D. student Sarah Fakhoury, we also report our experience in building LAPD using deep neural networks. We observe that although deep learning is reported to produce results comparable and even superior to human experts for certain complex tasks, it does not seem to be a good fit for simple classification tasks like smell detection.
Additional information:
- SANER’2018: Paper: Keep It Simple: Is Deep Learning Good for Linguistic Smell Detection?; Replication package: here
- EMSE’2015: Paper: Linguistic Antipatterns: What They Are and How Developers Perceive Them; Replication package: here